id gender age hypertension heart_disease ever_married \
0 9046 Male 67.0 0 1 Yes
1 51676 Female 61.0 0 0 Yes
2 31112 Male 80.0 0 1 Yes
3 60182 Female 49.0 0 0 Yes
4 1665 Female 79.0 1 0 Yes
work_type Residence_type avg_glucose_level bmi smoking_status \
0 Private Urban 228.69 36.6 formerly smoked
1 Self-employed Rural 202.21 NaN never smoked
2 Private Rural 105.92 32.5 never smoked
3 Private Urban 171.23 34.4 smokes
4 Self-employed Rural 174.12 24.0 never smoked
stroke
0 1
1 1
2 1
3 1
4 1 Stroke Prediction Based on Demographics and Medical History
INFO 511 - Fall 2024 - Final Project
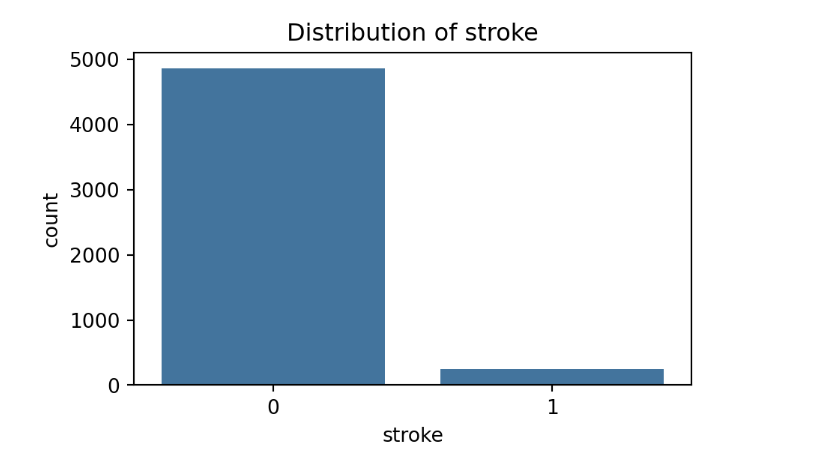
Visualization for Stroke Distribution
- Across the population, there is a higher proportion of people who do not suffer from stroke as compared to those who do suffer from stroke.
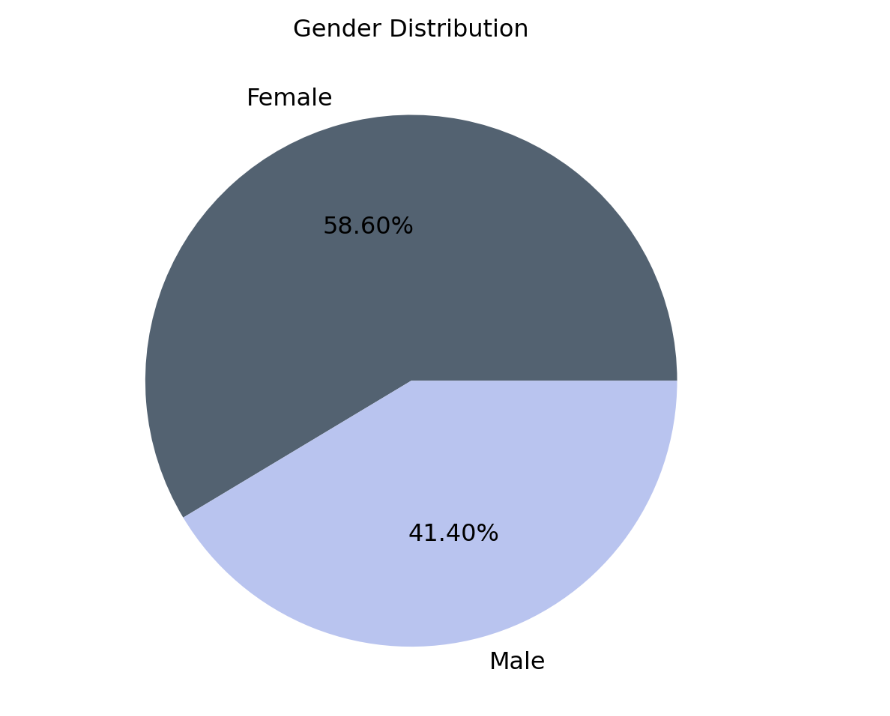
Visualization for Gender Distribution
- As for gender analysis, there is a higher proportion of females as compared to males surveyed.
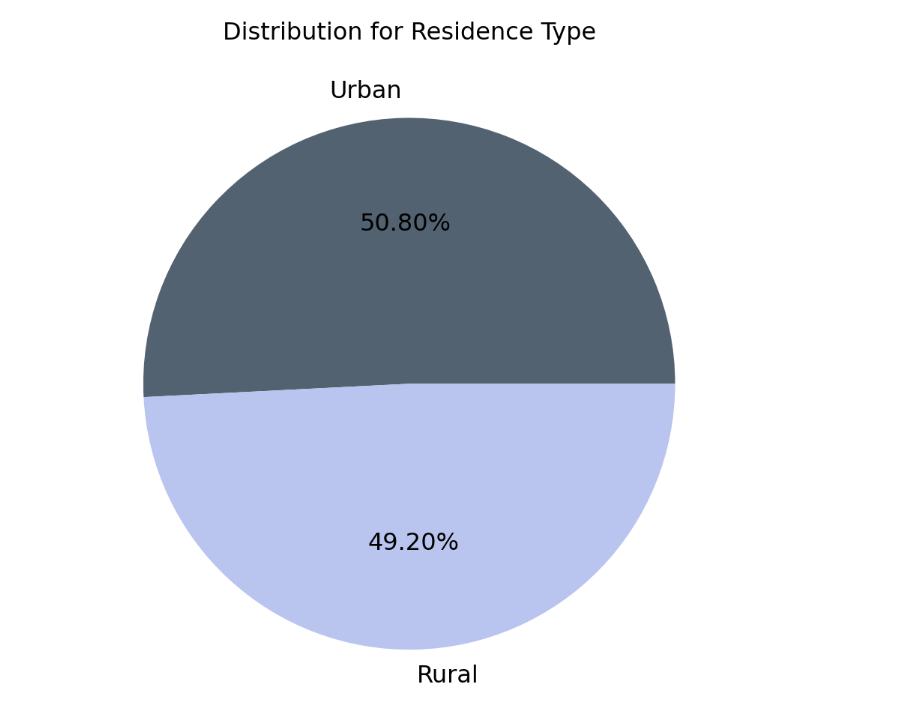
Visualization for Residence Type Distribution
- In terms of residence type, the distribution for rural vs urban are highly equivalent.
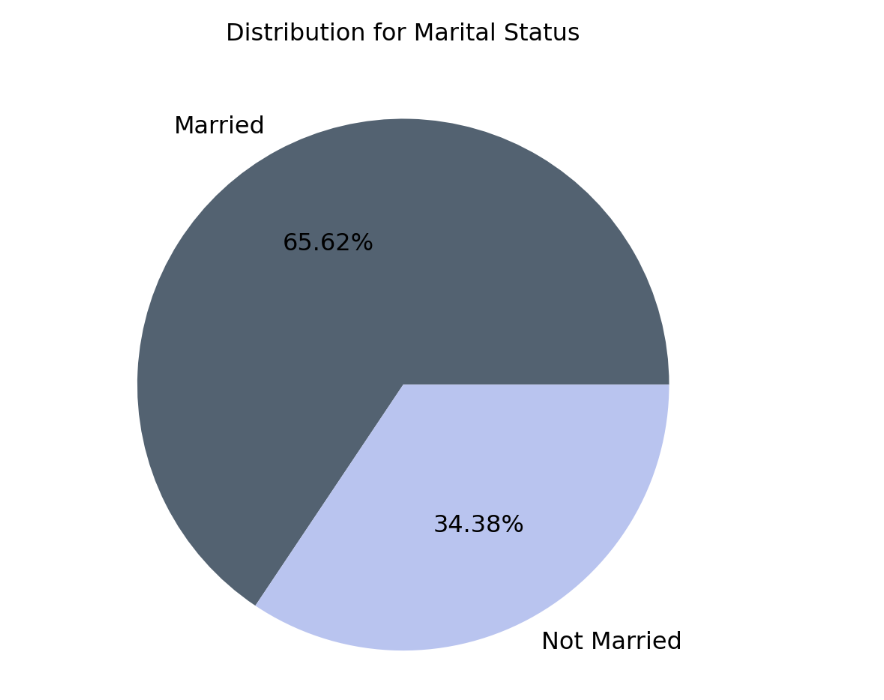
Visualization for Marital Status Distribution
- As for marital status, there is a higher proportion of people surveyed who are married, as compared to those who are not married.
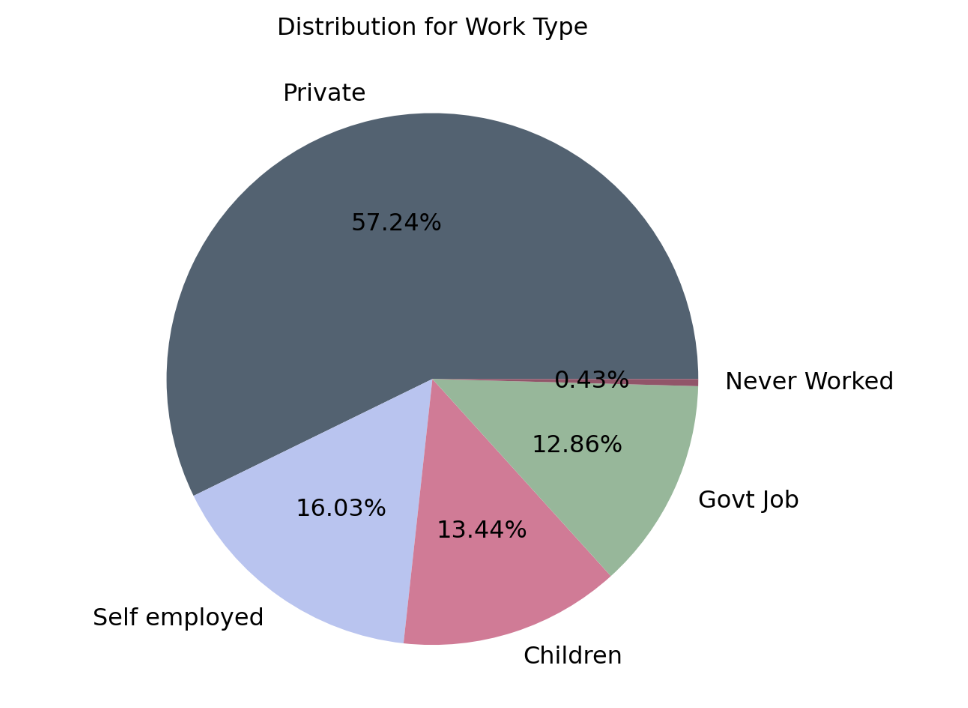
Visualization for Work Type Distribution
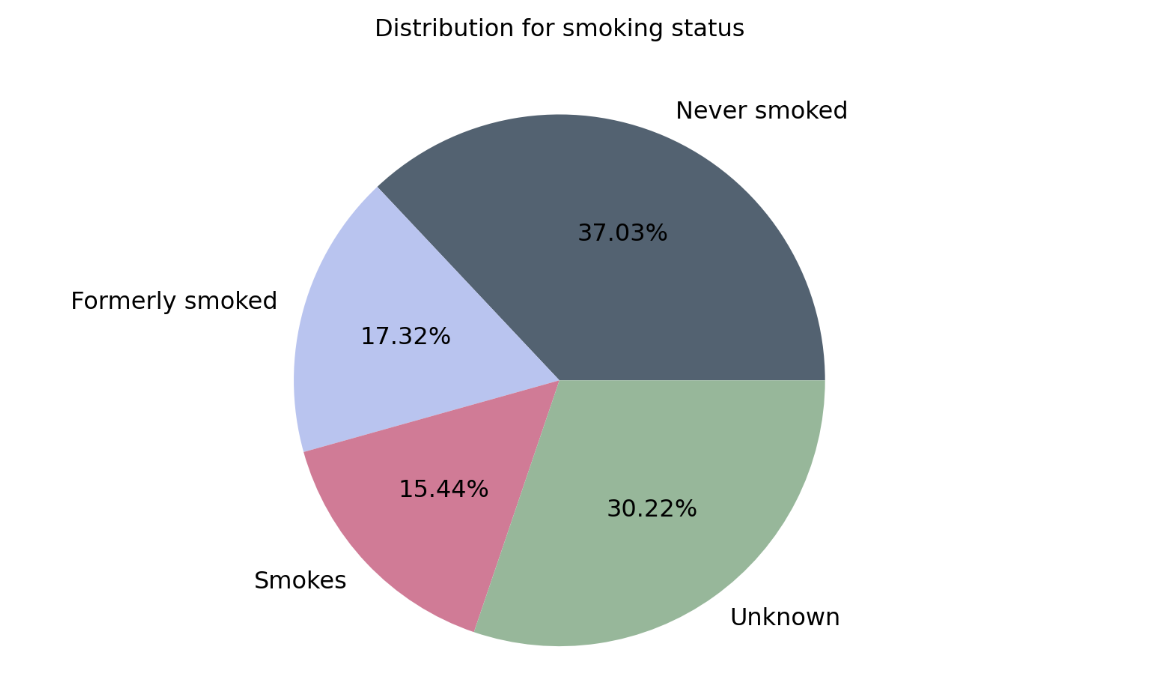
Visualization for Smoking Status Distribution
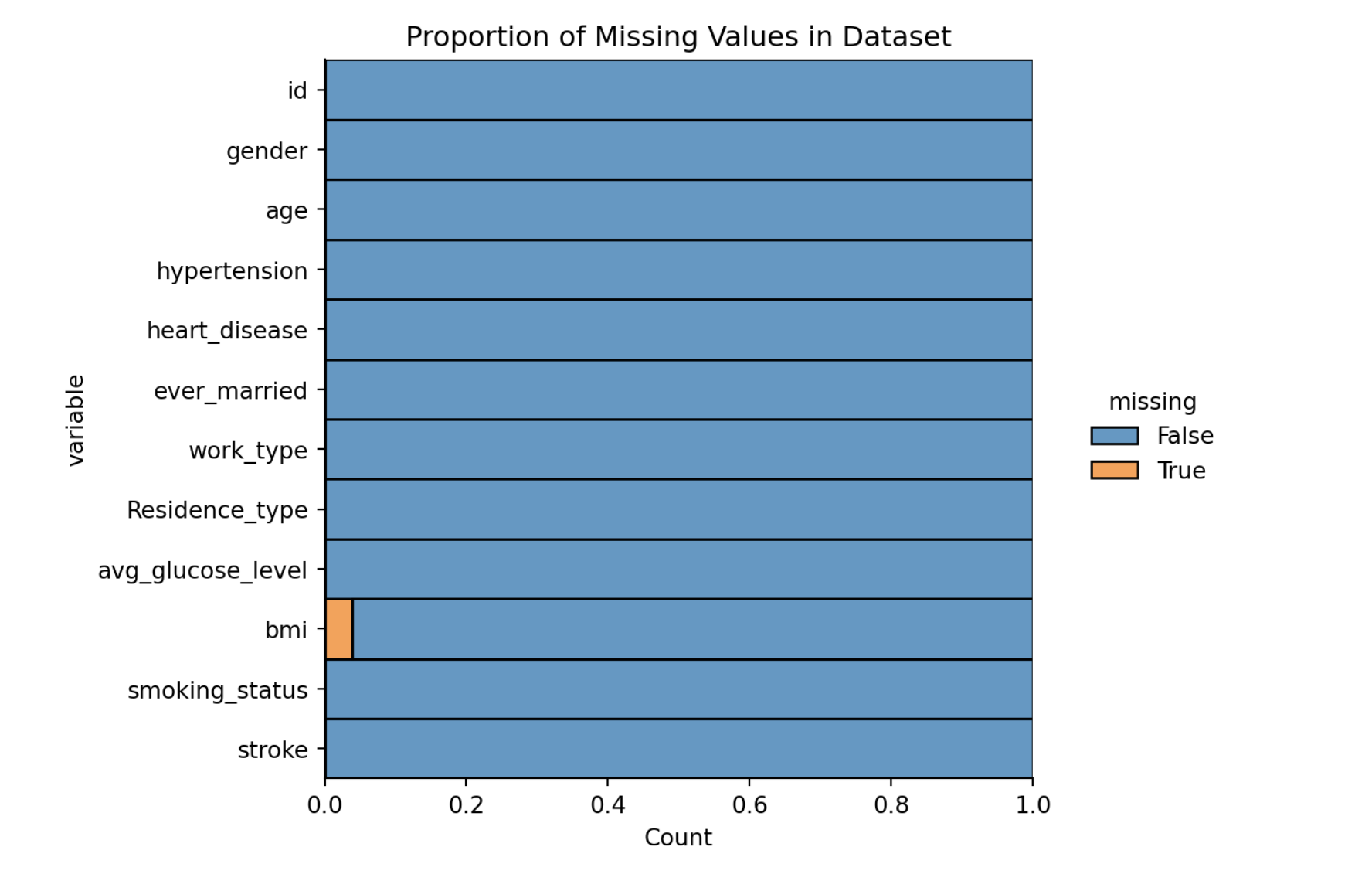
Exploratory Data Analysis
- Missing values were dropped from the dataset.
- Categorical variables were transformed into factors.
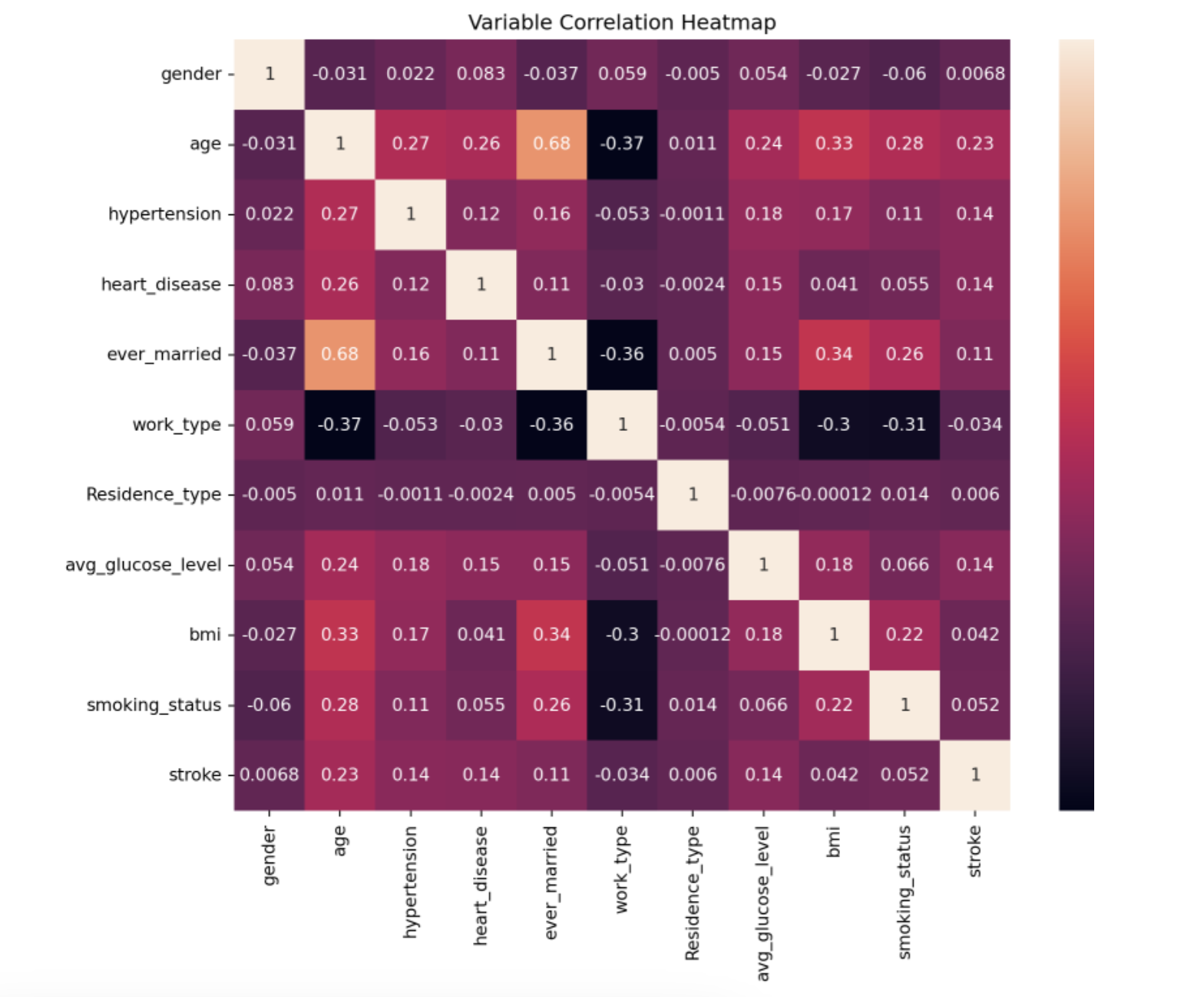
Variable Correlation Heatmap
- The correlation matrix of all variables, other the ID, is displayed on the heatmap.
Results